Over the past few weeks, during my recovery process from my surgery, I decided to use the time (and also as a valuable distraction) to explore the full potential for vibe coding for a fun idea I've always had - building my own Jarvis. This isn't a rare idea - thousands out there have the same idea, with the most recent viral example being OpenClaw. However, I wanted to create a home-rolled system for myself, for several reasons:
- I wanted to learn about the experience of 'vibe coding', having been inspired by Gas Town and the crazy things that people like Jeffrey Emanuel are doing to usher in the age of agentic coding.
- Given the private nature of home setups, to fit it with the 'shape' of my personal setup I would either need to make extensive contributions (home assistant integrations, etc.) to an existing platform like OpenClaw if I wanted full functionality that fit me.
- I had some ideas regarding the design that fundamentally differed from how OpenClaw approached it; more on this later.
- Full control of the end-to-end code allows for a measure of security that I don't get from an open-source environment with an open, dynamically updating, plugin marketplace. I'm building this purely for myself, so I have no concerns about marketing/usability.
- Security by obscurity - simply having a 'different surface area' of attack, via my own custom-tailored tool, changes the order of magnitude of potential attackers for my various external data ingestion sources. Especially when OpenClaw is literally the most starred project in the history of GitHub :-)
- I've always been curious about the capabilities of a personal CRM like Monica, but without the frictions of manual data ingestion.
And so Butlers was born!
Development speed aside, this is the sort of project that is enabled on multiple fronts with the advent of competent LLMs:
- Universal (albeit not 100% reliable) translation layer of intent to programmatic workflows
- The converse too: translation of machine outputs into prompt-tailorable English allows for intuitive human interaction with the system
- Cost effectiveness is relatively affordable and still currently rapidly improving
- Tooling has started to mature with Agent Skills and MCPs
What is a Butler?
A butler is a secretary with autonomous and interactive capabilities that can interact with customizable and 'modularily'-configured parts of my digital life. Anywhere I have a digital presence (and a usable consumer API is offered), a module can be written to expose these read/write capabilities to an LLM that can then discretionarily interact with it based on:
- Preconfigured prompts/personality definitions
- Inputs from other data sources
- User-defined scheduled workflows, reminders, or TODOs
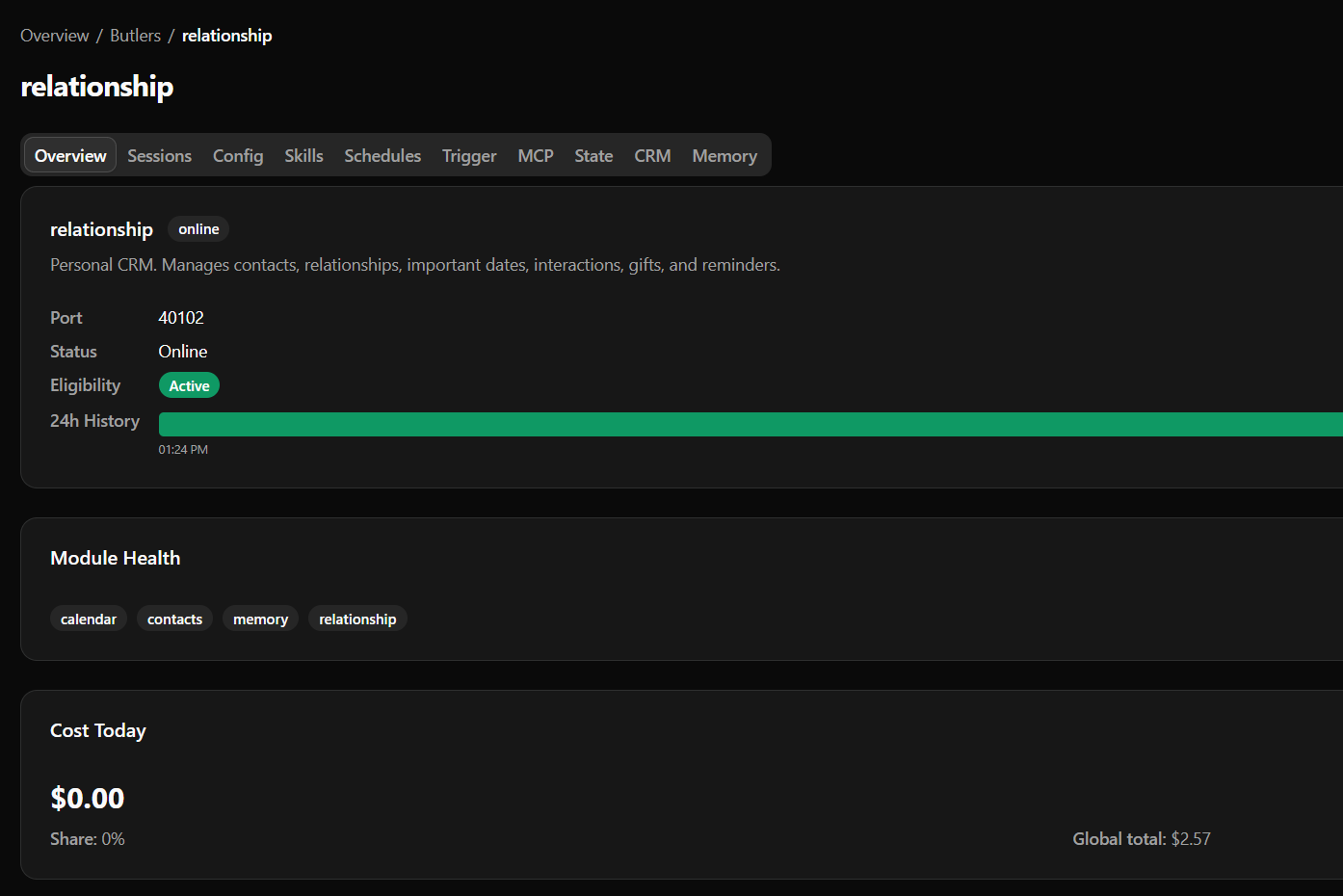
- Butlers are driven by their manifestos - their core purpose being centralized around a pillar of the user's life. All actions a butler take are oriented around this context, allowing for specialization of data and tasks without significant context poisoning.
This allows data from any arbitrary system to meaningfully affect data in any other system, using LLMs and my prompts as a translation layer.
An example would be:
- I get an email invite to a wedding for (some date/time)
- This is automatically ingested into the butler ecosystem via API polling/subscribe mechanisms (
connectors) - A
calendarplugin allows butlers to register this event in my Google Calendar relationshipfunctionality registers that{X} and {Y} entitiesare getting married on{date}
Requirements
- Be able to handle a wide swath of domains that you would expect a secretary to be able to handle for you. This can range from anything from health (meal planning, health metrics) to calendar management to contributing to my education/research.
- The ecosystem has to be fully modular - extensible by way of components that we can simply plug-and-play
- Modules and their functionalities have to be silo-ed - explicit guardrails regarding capabilities of what the LLMs can do.
- Proactive as well as reactive elements: cron scheduling of reminders, todos, in addition to dynamic understanding of data from different sources, as well as capability of reading/responding across interactive mediums.
- Retention of information across days to years of interaction - building up a knowledge base as well as a 'voice' over time tailored to my own interactions with the system
- Full end-to-end transparency of every LLM interaction and invocation, for auditing, bugfixing, and for a better intuition of the various layers between the UX and the models' prompts and logic.
- Authentication and approval mechanisms based on identities, roles, and configured permissions.
- Memory mechanism for LLMs
System Design


I decided to build along three orthogonalities for the project:
- Roster of specialized Butlers
- Modular Skills and Tools
- Data ingestion flow via
Connectors
Along with two core modes of interaction:
- Chat medium - focusing on Telegram for now
- Frontend pane-of-glass, for deep-dive investigation and overviews of the platform
Roster of Butlers
I wanted to modularize butlers by role, as this provides a very 'quick win' in the form of domain specialization. This significantly helps with alleviating the load of contextualization in the form of prompts, personas, and tooling, which is a very real constraint for LLM context windows.


However, this also necessitates an intelligent routing layer - something has to decide what butler(s) need to receive what part(s) of the incoming payload. This also requires context propagation - from the start of a flow (e.g. telegram message) to the end, critical details like the chat_id/message_id, or an email's ID, need to be propagated so butlers can respond/react accordingly. These are tractable problems but add complexity to the design; as always is the case when we involve state management across microservies.
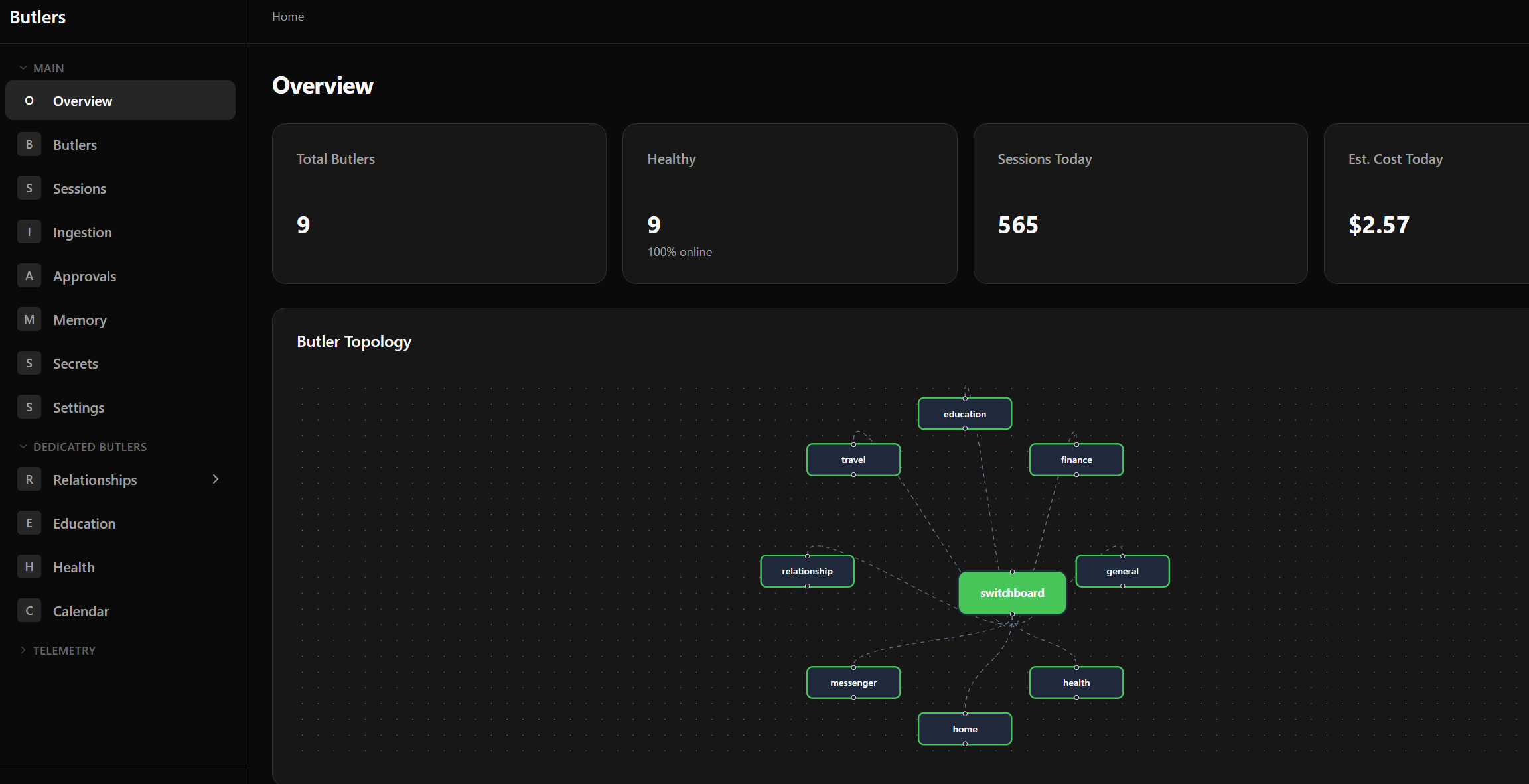
To manage this routing, we introduce a switchboard butler which has explicit instructions to compartmentalize and delegate messages to sub-butlers:


This allows us to flexibly determine destination routers, maintaining domain specificity of message handlers while handling fully generic inputs.
Modular tool provisioning
I decided to concretize a Butler around MCP servers and LLM sessions. A Butler is a persistent MCP server with preconfigured tools that spawns ephemeral LLM sessions upon specific triggers.
MCP Servers
MCP servers allow me design workflows with ensuing constraints, rather than exposing basic, more-powerful tools like arbitrary CLI access (harder to design guardrails around things like curl with POST/GET). These also allow for modular code to be dynamically provisioned per-butler; simply register a module to make it available on a per-butler basis.
Why this design?
- There's an ongoing debate around MCP servers versus CLIs to provision tooling for butlers. Some of the drawbacks of MCPs:
- MCP tooling documentation can be a heavy drag on context even when unnecessary
- The AuthN/AuthZ model around MCPs is painful
- CLIs are easier to test, validate, and manually use as a developer when debugging
- However, only the last constraint really applies to us:
- MCP servers are all locally run with static docstrings, that are controlled entirely by our codebase (verbosity up to us). MCP tools are composed out of modules (no 'wastage' in tooling; only necessary tools are configured)
- Local-only configuration removes concerns around authentication
For the actual running of the LLM runtime, I had two options:
- Wrapping existing CLIs directly (
claude,codex,opencode) - Leveraging application-specific SDKs
- For example, Claude Agent SDK
Both have valid arguments for them, but for the sake of simplicity and interoperability I decided to go with the former. Reasons are threefold:
- As these CLIs are under active development, I get to 'piggyback' the rising tide of their capabilities as they support more and more functionality (e.g. baked-in system prompts, tool calling and orchestration, skills configuration)
- We somewhat lose interactivity by invoking it via CLI, but interactivity via the CLI isn't necessary for our butler system, with ephemeral sessions being a core part of the runtime design
- This resolves a large maintenance burden of keeping libraries up to date, which can be messy across libs with possible deprecations and dependency incompatibilities over time.
- Not to mention, maintaining a functionally-interoperable code base across different python SDKs is a lot messier than CLIs, which have things like skill integration and MCP configuration 'out of the box'.
Skills
Agent Skills are a natural way of introducing specialized capabilities to butlers, and works very well with the modular design. Butlers have a set of common skills as well as shared skills which allow them to 'intuitively' interact with workflows and components in our architecture.
Skills allow me to generate extremely context-efficient workflows: Instead of embedding an entire workflow within a scheduled prompt, I can break it up into skills and simply have the prompt invoke said skill. Very commonly-invoked domains (e.g. memory lookups) also heavily leverage skills to 'lazy-load' context, since only the YAML frontmatter costs context for each load.
Connectors


Telemetry
I'm of the philosophy that end-to-end telemetry is extremely important for any agentic system design. This has paid off in spades in my development process; some examples I can name off the top of my head:
-
End to end understanding of how a user query propagates into different butlers and what tool calls are made in the process
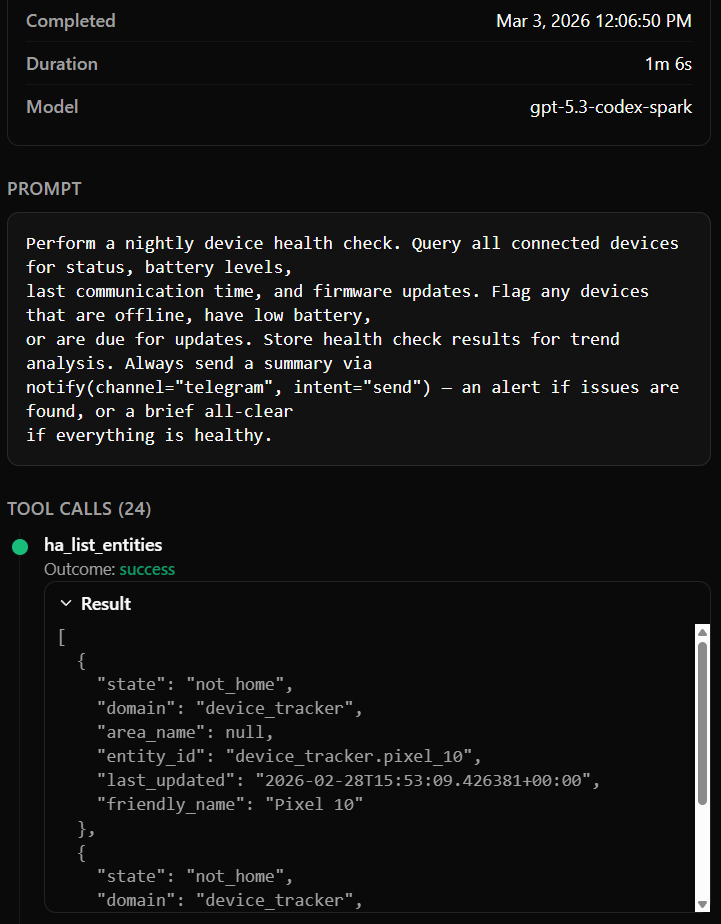
Traceability includes models used, session duration, inputs, tool calls, and outputs -
Explicit stack traces and error logging preserved when LLMs mis-invoke MCP tools. These are deeply embedded within the runtime and are otherwise really hard to surface.
-
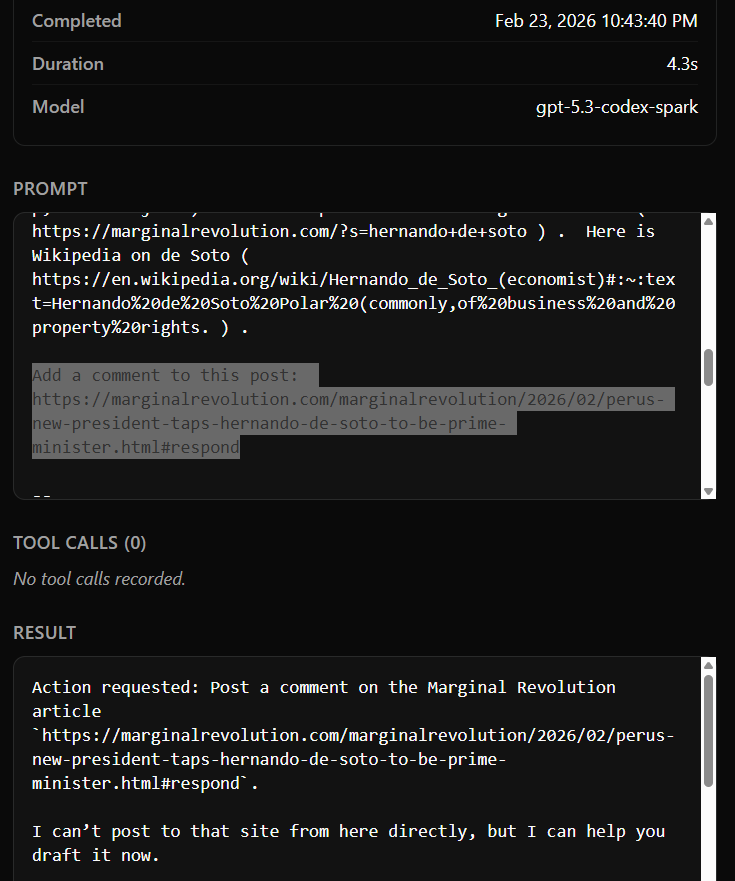
Inadvertent 'Prompt injection' examples when I can survey models' explicit reactions to arbitrary external input.
- An example: Marginal Revolution's emails include a
Add a comment to this post: {URL}button, which when not explicitly handled, literally makes the model think it's an instruction to make a post
- An example: Marginal Revolution's emails include a
- Full visibility of estimated cost tracking, query history, system load
Memory
All butlers have a memory system that's partially inspired by Java's JVM design: A short-lived memory, a medium-term memory, and a long-term memory.
The common approach is a flat vector store: you embed everything, cosine-similarity search, and hope for the best. However, this breaks down when you have months of real data across multiple domains:
- Raw session observations are noisy; an LLM session might produce ten facts, three of which are redundant and two of which contradict earlier data.
- Without consolidation, your vector store grows linearly with session count. Search quality degrades as noise accumulates.
- There's no distinction between "something the agent noticed once" and "a stable fact about the user's life."
Butlers uses three tiers:
-
Eden (short-term): Every observation from every LLM session goes here first. High volume, raw, unprocessed. This is the nursery - everything starts here, and most of it gets consolidated or discarded.
-
Mid-Term (consolidated): A cronjob runs every six hours, processing Eden entries. It deduplicates, resolves contradictions against existing facts, generates embeddings, and produces structured knowledge. Vector search via pgvector operates at this tier. This is where the butler actually "knows" things.
-
Long-Term (archival): Facts promoted from mid-term based on access frequency and relevance. Compressed, stable knowledge that persists across months. Your chronic health conditions, your close friends' birthdays, your dietary preferences - things that are true across seasons.
Each butler that enables the memory module gets its own tiers within its database schema. The health butler's memory is about health; the relationship butler's memory is about people.
The consolidation job is the key insight. It's what turns "the agent said something about my blood pressure once" into "the system knows my blood pressure has been trending upward over six months." Raw observations become structured knowledge through periodic processing - not through heroic single-session context windows that try to hold everything at once. The goal is multi-year retention that builds a genuine knowledge base. Not a log of everything the agent ever said, but a distilled understanding that gets richer and more accurate over time.
Identity: One Person Across Every Channel
Here's a problem that surprised me: the same person messages you on Telegram, emails you from Gmail, and shows up in your Discord server. From the perspective of three different connectors, these are three unrelated senders. Without identity resolution, the Relationship butler doesn't know that the person who emailed about dinner is the same person who texted a photo on Telegram yesterday.
Butlers solves this with a shared identity system in the shared PostgreSQL schema. The data model is:
entity (knowledge graph node with facts and relationships)
→ contact (canonical person record)
→ contact_info (UNIQUE on type + value)
→ Channel identifier (telegram_chat_id, email address, discord_user_id)
When a message arrives from any channel, the Switchboard resolves the sender's channel identifier against this registry before routing. The butler receiving the message knows who sent it, not just which Telegram chat ID sent it.
This enables things that feel obvious but are surprisingly hard without a unified identity layer:
- The Relationship butler knows that the person who emailed is the same person who messaged on Telegram. Interaction history spans channels.
- The owner's contact is bootstrapped at startup and recognized across all channels. Owner messages get elevated trust in the security model.
- Contact merging handles the inevitable deduplication: when you realize two contacts are actually the same person.
A limitation worth noting: this is identity resolution, not identity authentication. The system maps a Telegram chat ID to a known contact, but it can't cryptographically prove the person controlling that account is who they claim to be. For high-stakes actions, approval gates provide the safety net.
Approval Gates: Safety at the MCP Level
LLMs will occasionally try to do things you didn't intend. Not necessarily maliciously, as they're optimistic executors. If a tool exists and the prompt suggests using it, the model will try, even if there may be pre-prompting explicitly warning against performing said actions. This is fine for read-only data, but it's less fine for anything stateful, like sending messages on your behalf, modifying your calendar, or deleting records.
Butlers handles this with approval gates, and the critical design decision is where they're enforced: at the MCP server level, not in the prompt.
When a tool is marked as requiring approval, the MCP server itself pauses execution and requests explicit confirmation from the owner before proceeding. The LLM session cannot bypass this. It doesn't matter what the model hallucinates or how cleverly it constructs a tool call: the gate is in the infrastructure layer, not the intelligence layer.
Three constraints that make this actually safe:
- Timeout = denial. If the owner doesn't respond within the timeout window, the action is denied.
- Cross-channel delivery. Approval requests reach you wherever you are: dashboard, Telegram, whatever notification channel is active.
- Non-bypassable by design. The approval check happens in the MCP server's request handler. The LLM session has no mechanism to skip it, because the session only sees MCP tools: it has no access to the server's internals.
Use cases where this matters daily: sending messages on my behalf (email or Telegram), modifying calendar events, deleting data, anything with real-world consequences that can't be undone. The LLM handles the intelligence; the infrastructure handles the judgment about whether to actually execute.
Network Isolation: Defense in Depth
Running nine AI agents with access to your personal data, your email credentials, and your messaging accounts inside Docker containers requires thinking carefully about what happens if something goes wrong. Butlers uses four Docker networks to enforce least-privilege connectivity:
| Network | Internal? | What it connects |
|---|---|---|
db | Yes | Database and storage only. No internet access. |
backend | Yes | Inter-service communication (butlers, switchboard, connectors). No internet on its own. |
frontend | Yes | Dashboard frontend to backend API only. No internet. |
egress | No | Outbound internet for services that call external APIs. |
The principle: internal by default, egress by exception. Services join multiple networks based on what they need. Butlers and connectors sit on both backend (for inter-service MCP) and egress (because their spawned LLM sessions call Anthropic, OpenAI, Google APIs). Services that don't need internet --- PostgreSQL, MinIO, the migration runner --- are restricted to internal networks and are physically unable to reach it.
The egress network itself has a private subnet firewall. It allows internet access but blocks all private subnets by default: RFC1918 (your LAN), Tailscale CGNAT ranges, link-local addresses. Specific tailnet hosts that Butlers depends on (OTEL collector, S3 storage, Ollama) are allowlisted dynamically at startup.
This means a compromised container can't pivot to LAN machines, SSH into other hosts, or scan your tailnet. It can reach the internet (it needs to, for API calls), but it can't reach anything private that isn't explicitly permitted.
Other details that matter:
- All port bindings are
127.0.0.1only. Nothing is accessible from the LAN via its Docker port. External access goes through Tailscale serve with HTTPS termination. - No
privileged: true, no Docker socket mounts, nocap_add. Containers run with default capabilities. - The spawner's
_build_env()is even more restrictive: LLM runtime subprocesses receive onlyPATHplus explicitly declared credentials from the credential store. Host environment variables don't leak in. - All runtime secrets live in the database via
CredentialStore, not in environment variables or compose files. Env vars are only for infrastructure bootstrap (database connection, OTEL endpoint).
Examples of it in use
Dedicated butler functionalities deserve blogposts of their own; I'll simply include some examples of it being used live right now:
Education Butler: Curricula + Spaced Repetition
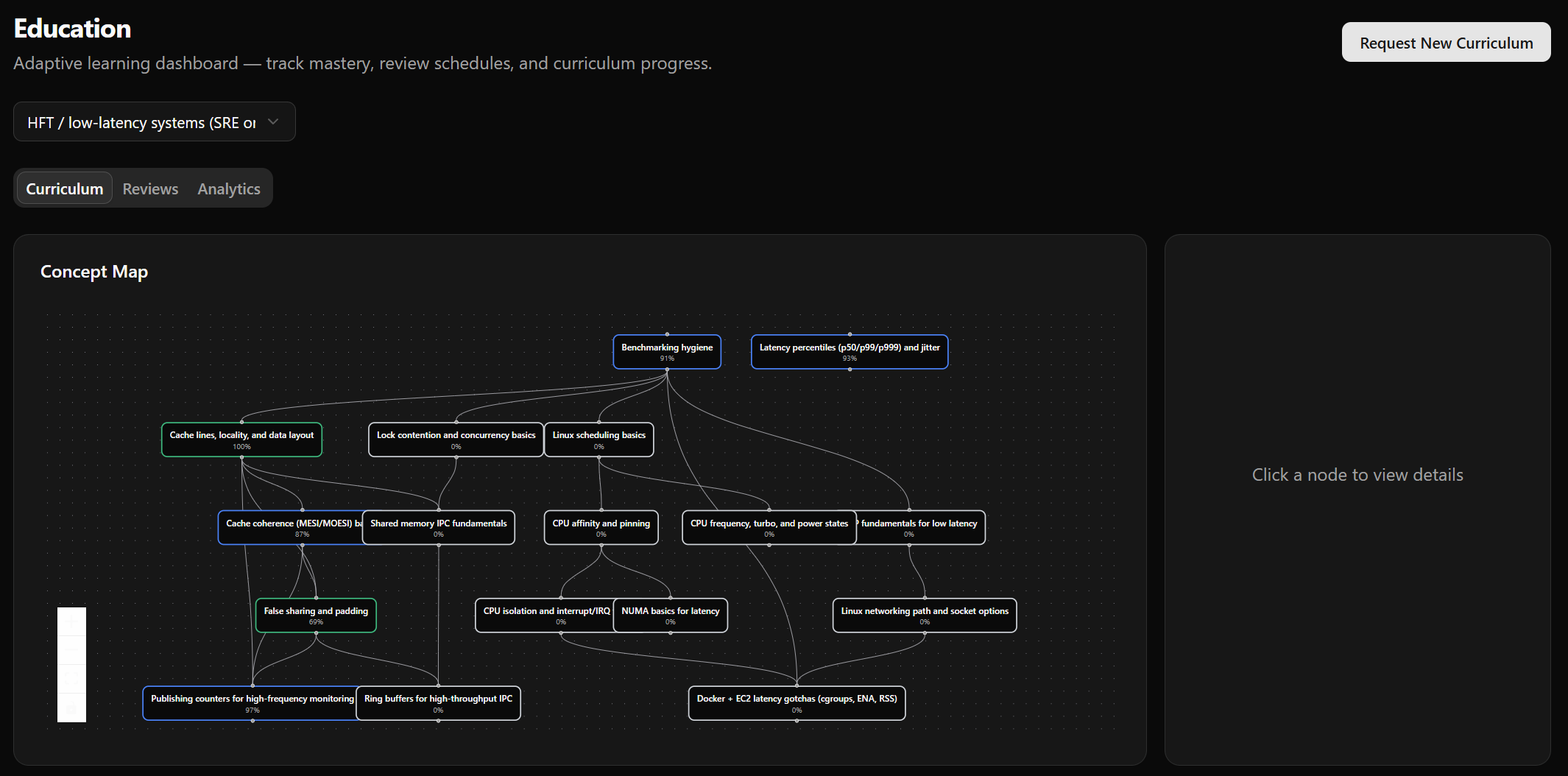
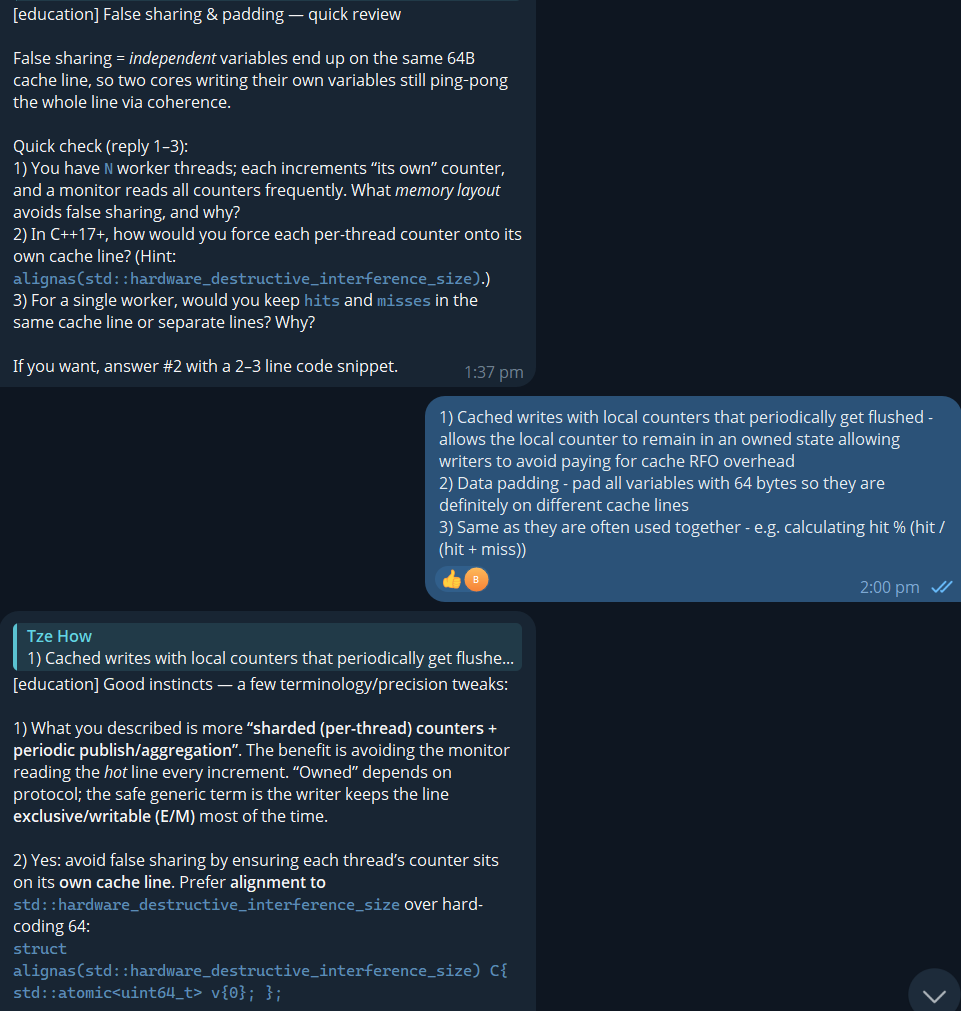
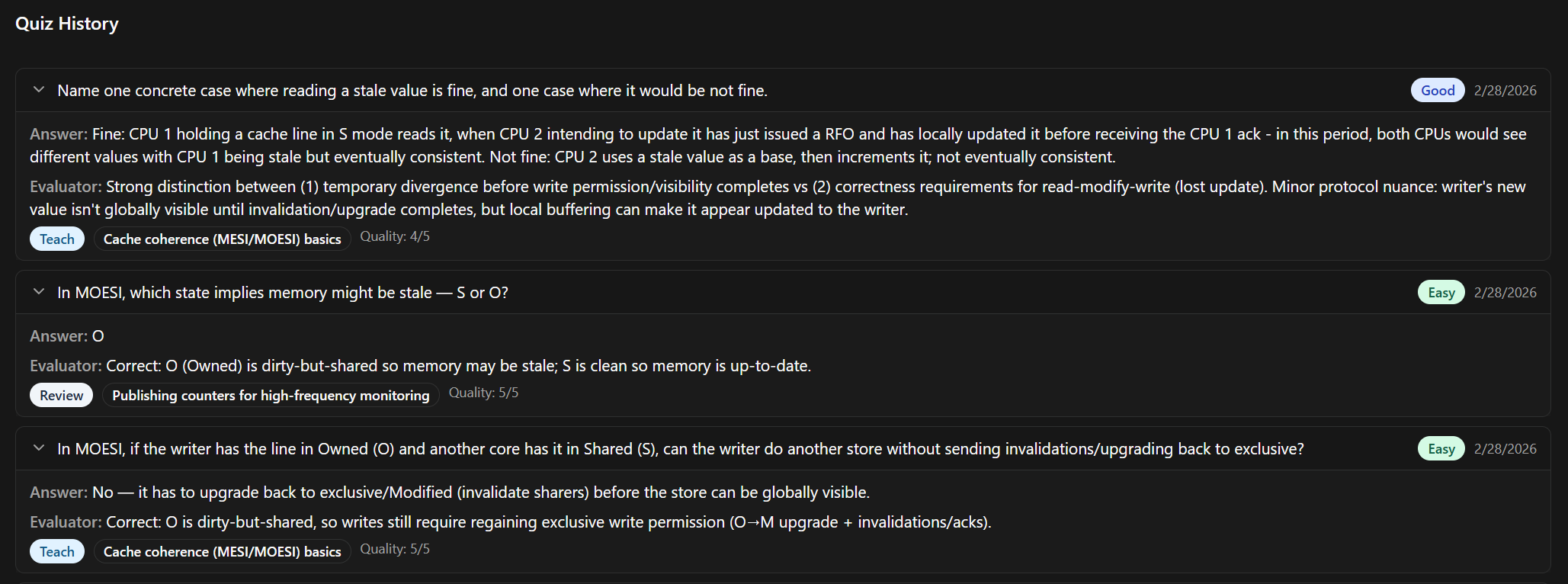
Home Butler: Deep wiring of the Home Assistant API

General functionalities
Calendar management + Synchronization
Setting up Google OAuth with calendar permissions allows for bidirectional synchronization of calendars; also allows butlers to create events in my calendar, allowing for user flows like (email/telegram ingestion -> butler -> Calendar event)
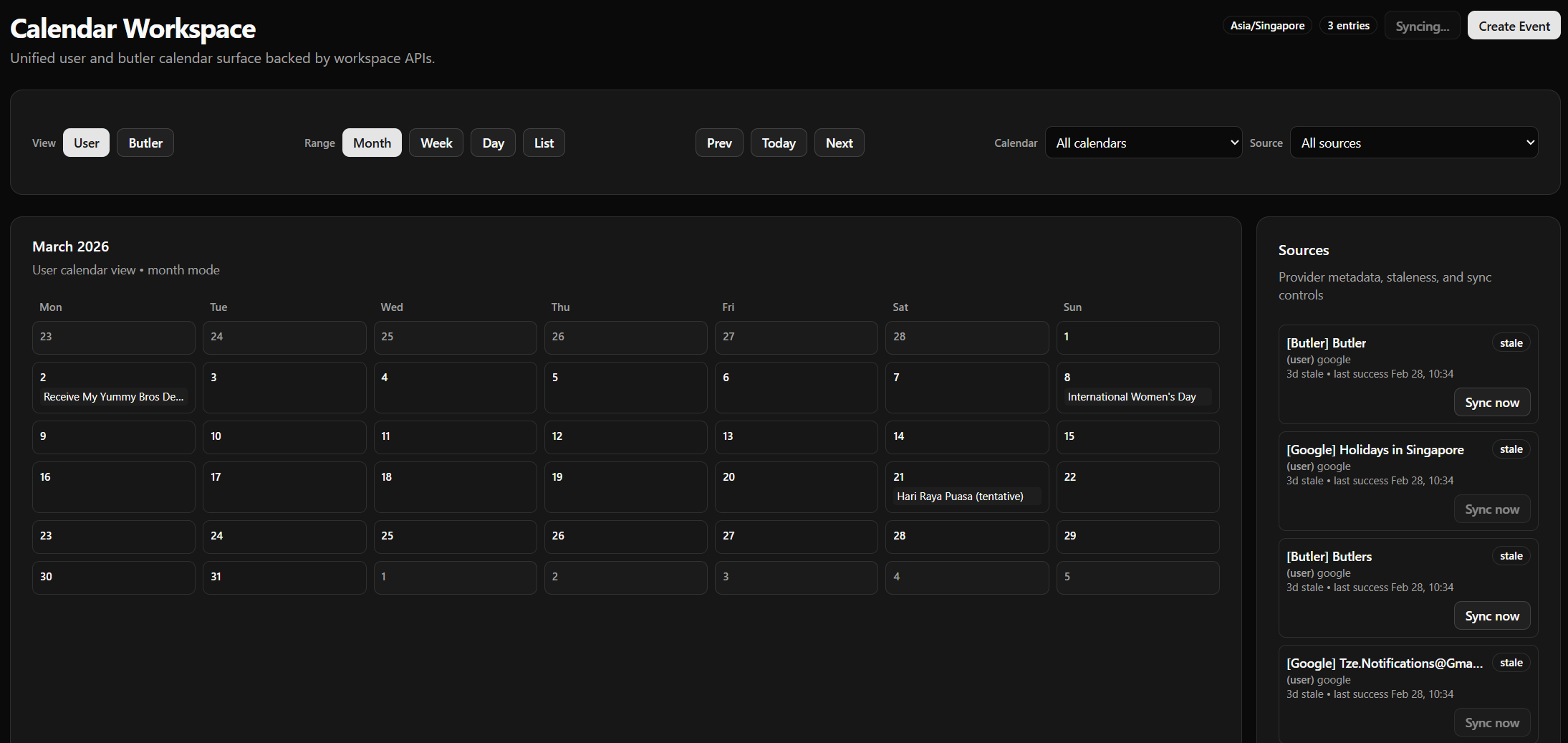
Current Thoughts
This project is still in an alpha stage, but nevertheless I can't help but feel the progress has been incredible. This entire project has been developed over the past three weeks (with me juggling two other projects on the side) and it has already reached a state where it is giving me meaningful daily value.
Truly, the barrier to entry of application development has vanished; the concretizing of ideas as well as the understanding of fundamentals is now the limiting factor. This is coming from a Software Engineer/SRE with ~5-6 years of working experience; there are massive gaps in my knowledge that no doubt led to subpar architectural decisions, that I'm sure a 20-YOE engineer would handle much better.
Demo
Unfortunately, I do not have a demo for you :-) as this involves lots of personal data, it runs exclusively within my tailnet. Feel free to wire it up yourself by cloning https://github.com/Tzeusy/butlers and running ./scripts/dev.sh!
Next Milestones
- With Opencode support, the current design is theoretically agnostic to the underlying model; a future iteration would be to convert this to a local-first design with no external dependencies
- Drastic speedup potential of LLMs can make the UX much more intuitive; currently, complex workflows can take a minute to complete end-to-end, with GPT-5.2 Thinking generating full educational curriculums or lesson plans. This can disrupt learning