In this post
- Why agent alignment becomes the bottleneck in multi-agent development
- Why doctrine matters more than preserving the accidental current shape of a codebase
- Why specifications and mental models need their own explicit artifacts
- The five project-alignment pillars: doctrine, design contracts, capability specs, topology, and engineering standards
- How
project-shapeturns those pillars into a reusable documentation workflow
Project Management and Planning
A Project's Shape: The Mandate of Alignment
When working with agentic workflows, keeping individual (and often unsupervised) agents aligned to our requirements often becomes the primary constraint. Divergent agents are often useless, or sometimes even actively harmful, to the rate of development of the project; agents misunderstanding an intent can spawn other agents with the misunderstood intent, leading to a broken telephone line of work that has to be entirely scrapped (if it can even be detected!). Just to name a few instances:
- Agents outputting gibberish after 250k-500k (anecdotally) tokens due to context rot and needle-in-haystack degradation
- A rogue agent once deleted my entire dev database while trying to re-bootstrap my docker-compose setup
- Agents working in the same git folder often liberally run destructive commands like
git stashandgit reset --hard; even with explicit instructions to work in their own worktrees
I came up with two core ideas for tackling this over long contexts and multi-agent workflows:
Working with the spirit and not the letter of the law
Through my journey working with AIs so far, I've noticed several 'AI smells' that inherently contradict my own instincts for good and practical engineering.
1. Liberal use of shims for preservation of backwards compatibility
I've found that LLMs tend to over-respect Hyrum's Law; when a function is changed, it will often go to unreasonable ends to ensure the 'previous shape' persists in the system, so nothing depending on it can break. This might provide short-term relief for maintainers; a release can't go wrong if all production dependencies are preserved, after all. However, this pattern tends to cause the codebase to evolve into absolute gobbledegook over time. Some examples:
- Changing a function signature: For backwards compatibility, overload the method and preserve the old signature
- Changing a function location: For backwards compatibility, import and re-export the module from the old location
- Changing a module: Import and re-export everything via
__init__.pytricks
These add nothing to the functionality of the code, and simply add to the unreadability, all in the name of stability. This is an example of respecting the letter of the law (existing import/export/dependency chains) rather than the spirit of the change (I want to refactor my module, and refactor all the imports too, damnit).
2. Tests pass good. Tests fail bad. Do anything to make tests pass
LLMs can take objective-driven approaches too far with code. When the goal is simply 'Make our CI pass', they can resort to shims like faking entire sets of data in the test suite to make an integration or e2e test pass. They also often try to get around failing tests by testing for exact inputs and outputs, rather than understanding why a test was written.
Getting an AI to understand the intent of the code is important, because it shapes the consideration going into every session of how it writes code. Emphasizing why a change needs to be made, because this is what the project's goals are, and this is how we want to do it, allows it to reason from first-principles of "Do the project well; subtask X is a requirement" instead of "Achieve subtask X by any means necessary".
Specification Frameworks
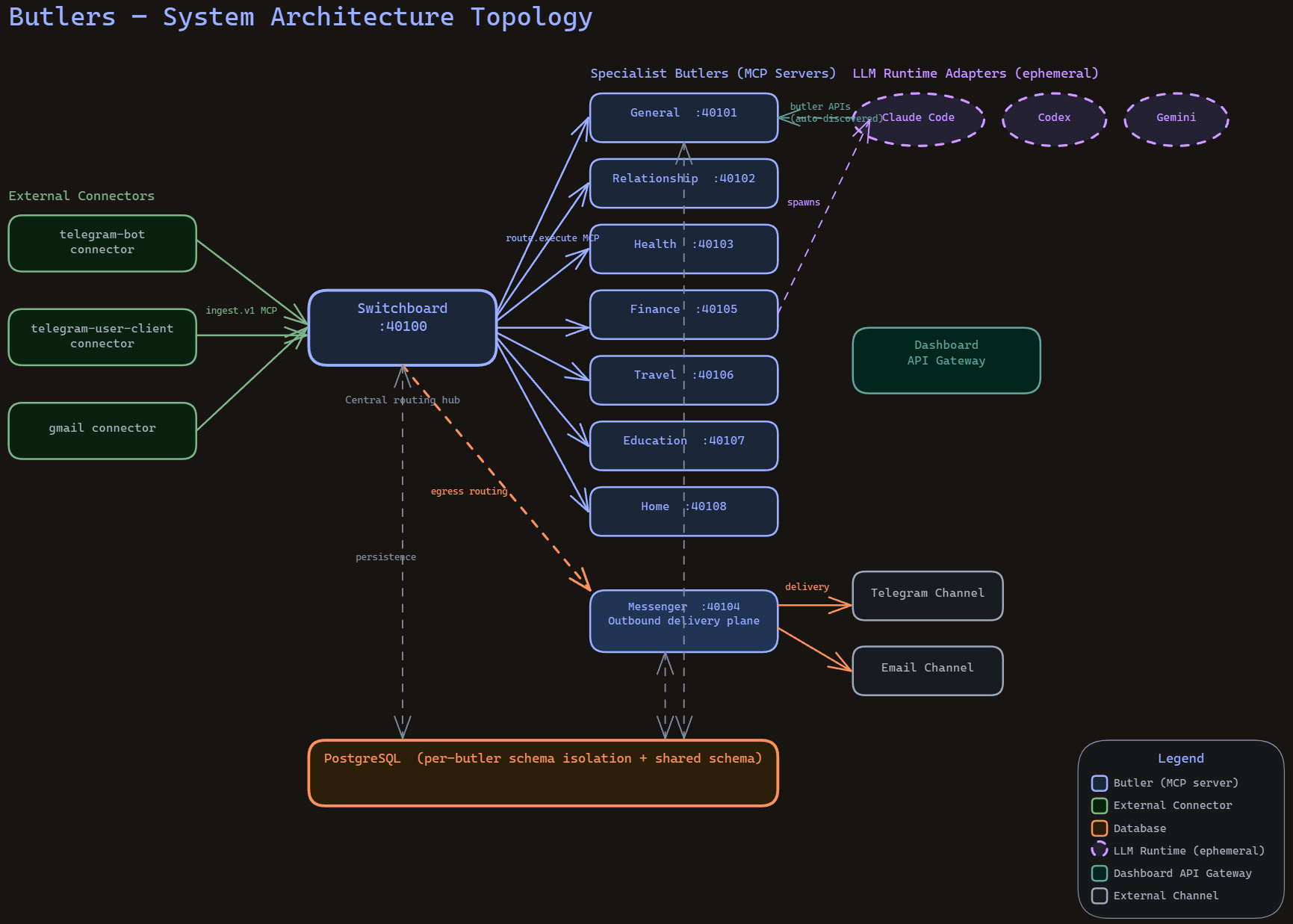
I have found Spec Driven Development to be one of the most important parts of maintaining a large, growing, contextually difficult piece of code. Heavy engagement with LLMs on specifications allows us to thrash out lots of possible failure modes and misconceptions before they make it into concretized code. Wrongly aligned code can often have extremely tangled recovery processes; database schema decisions, or bad data in the system, can all have very, very difficult and messy recovery processes.
LLMs are fantastic at communication, great at incessant hammering away at a task, and good at brainstorming (within existing technical capabilities). All three lend to its capability of generating human readable documentation to mandate what an application needs, without any underlying code having been generated. This also allows me to hash out edge cases in what is essentially pseudocode, before we get down and dirty with technical details. Technical constraints are rarely hard constraints on functional requirements of a system; the implementation of the code hence rarely impacts the functionalities that we can achieve with simply our ideas. For use cases which require straining technical capabilities - low latency programming, for example - specifications can mandate latency, and THEN the code can be shaped to achieve said requirements.
Mental Models
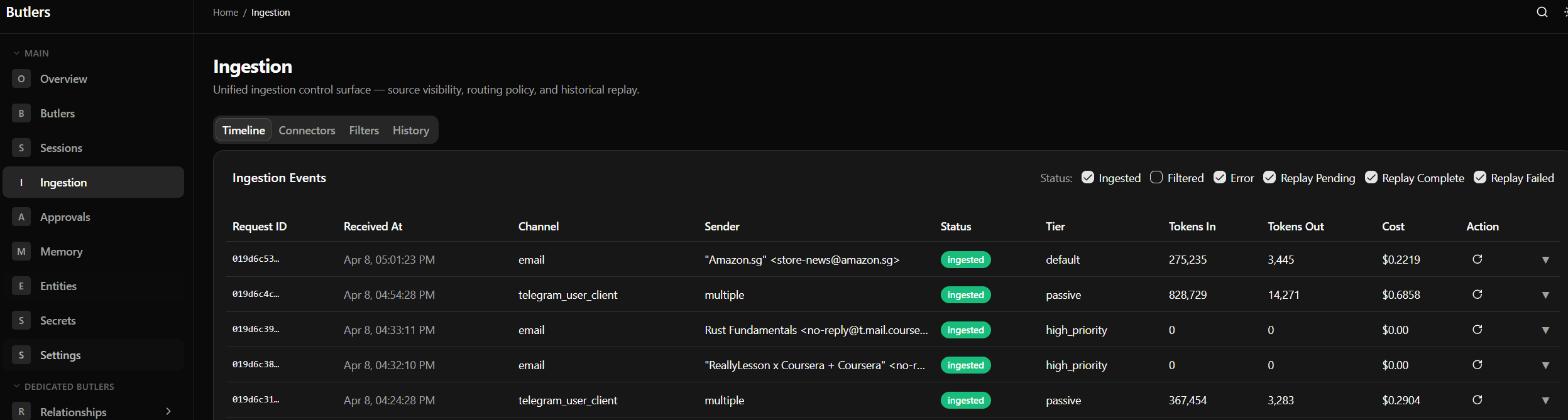
With the absolute sheaves of code being written by LLMs, I have turned to LLMs to aid me in being able to keep updated mental models of the system in my head. This is an ongoing battle: As applications grow more complex, the UXes for understanding the code and the intermediate states of the system must evolve with them. I have found in my experiences that setting requirements for code legibility, observability, and transparency have been critical in helping me to continue with keeping mental models of my systems in my head as a system runs day to day. WHERE is everything??
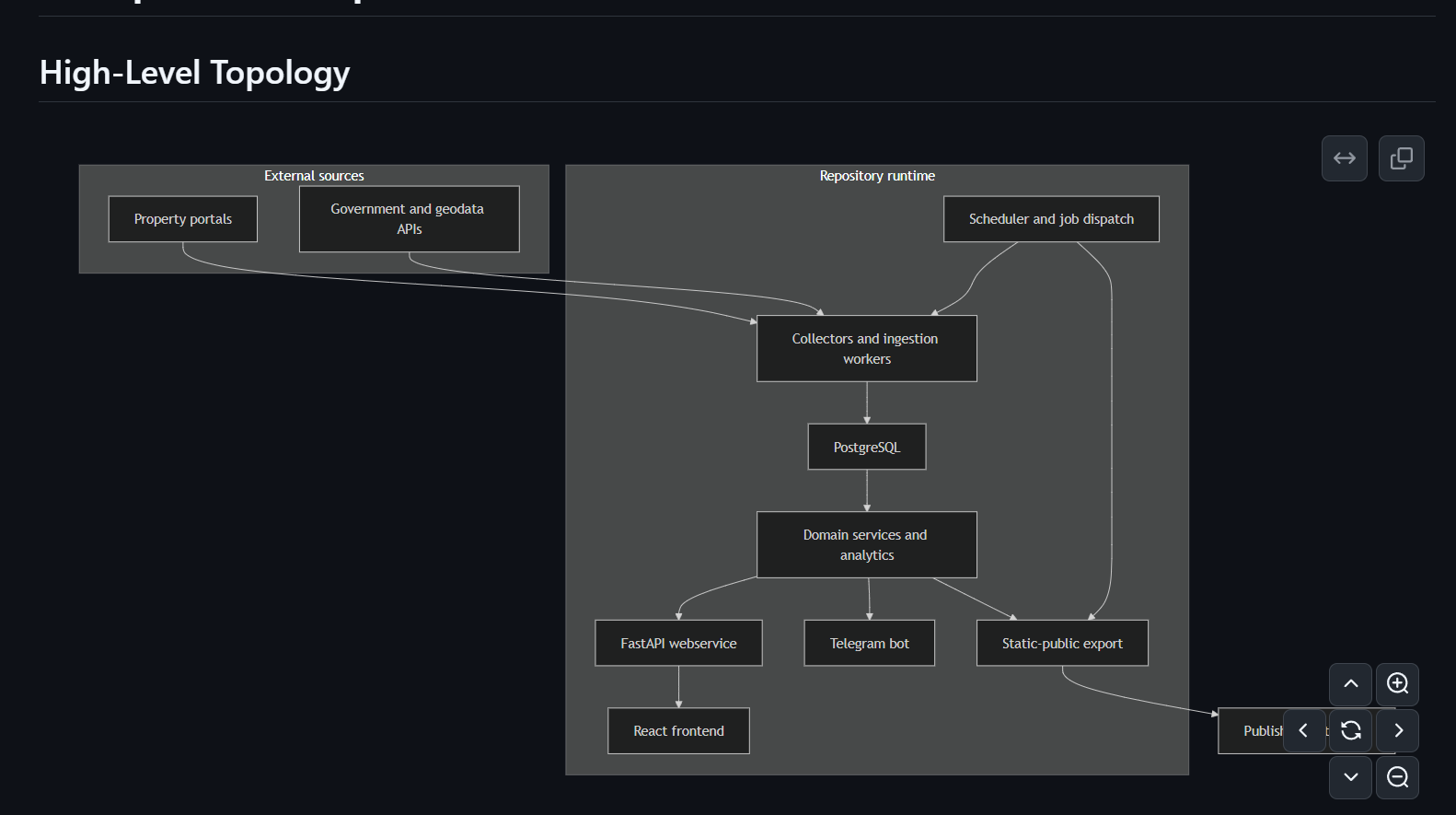
By generating diagrams, I can help both myself and future readers understand the logical flow of data and the infrastructure better. This allows me to reason with LLMs and provide subsequent guidance and direction without contradictory ideas that are incompatible with the system (or would require major redesigns, which an LLM would happily do).
The Five Pillars for Project Alignment
To achieve this, I created the concept of a project-shape skill, which serves to drive a spec-driven shape, or pillars underlying a project. I named the concepts normatively; hopefully in a self-explanatory way.


The Heart and Soul
Metaphorically: These are the commandments of the project; the internalized understanding of a mission, enshrined by an authoritative being (in an initial deep consultative session with an LLM).
The heart and soul of a project drives the underlying doctrine. Why does this project exist? What is the problem that we are trying to overcome? This pillar represents the manifesto and the mission statement of the repository; any changes made should be made in service of furthering that goal. This pillar takes precedence over everything else, as it is the ultimate boiled-down spirit of what the project is trying to achieve.
Having a LLM understand this allows it to make judgement calls in its development process for decisions that bias in favor of solving the 'bigger picture' problem. That sounds obvious when written down, but it matters a lot in practice. Without an explicit doctrine, every future change is incentivized to take the locally convenient route. Need a new workflow? Jam it into one tool's prompt. Need a workaround? Hand-edit the mirrored copy. Need some local state? Commit it and tell yourself you'll clean it up later. A month of that and the repo stops encoding principles and starts encoding accidents.
On a meta-level, this 'heart and soul' concept also applies to this repository. For this repo, the doctrine is basically: A centralized, vendor-agnostic collection of LLM-oriented tooling, designed for portable AI-assisted development. Shared workflow logic belongs in skills/. My own local operating model belongs in skills/personal/. Tool namespaces like .claude/, .codex/, .gemini/, and opencode/ exist as thin adapters around the canonical layer.
The "heart and soul" documents are there to make some rules non-negotiable:
- The vision and core thesis of the project is the North Star of the project
- Projectwide inviolable principles are enshrined and trip 'planning circuit breakers' when run through
/project-direction - Workflows and development prerequisites are consulted before any LLM-driven development
The Legends and Lore
Metaphorically: These are the 'stories' of the project; the tales of what practices to follow and bounds not to cross, handed down over generations of historical LLM sessions. As with fables, different combinations of heart-and-soul mandates underlie the 'morals' of these 'stories'.
Between the promise of a project and its implementation there are many translation layers; a promise (e.g. 'high performance') alone isn't enough to fully align development within bounds previous sessions have set (e.g. 'use this specific transport layer'). To enforce this, a /legends-and-lore is introduced that enforces the usage of RFCs to shape technology requirements and platform concepts like object lifecycles.
That is what the legends-and-lore layer is for: it turns the spirit into design contracts. This means RFCs that explain the structural agreements the repository is expected to uphold. Which directories are canonical? Which ones are mirrors? When is tool-specific divergence legitimate? How do symlinks and home-directory installs work? What kind of runtime state is explicitly outside the contract?
I have found this to be important with AI tooling because these ecosystems mutate very quickly. If there is no written contract, every new tool feature exerts pressure to reorganize the repo around itself. The legends-and-lore docs keep the repository shape deliberate as adapters evolve with each vendor's affordances. The lore part of legends-and-lore is effectively all the sharp edges that a future-me or future-agent would otherwise re-discover the hard way.
The Spec and Spine
Metaphorically: This is the backbone of the project, the normative definitions of functionalities worked out over synthesis of the motives (heart) and the standards (legends) set out above. The spec-and-spine layer answers the question: alright, if these doctrines and contracts are real, what must be true in a way that can be checked?
This is where openspec/ comes in. I use it to turn a repository shape into normative requirements and change records instead of leaving it as aspirational prose. A proposal says why a structural change is happening. A design doc says how it is intended to work. The spec says what properties must hold if the repository is still considered coherent afterwards.
I like this separation because it prevents a common failure mode in AI-assisted development: a repository can feel well-explained while still being underspecced. Everyone "gets the idea", until the implementation has drifted and nobody can say whether the current shape is still valid or merely familiar.
OpenSpec gives me something more concrete:
proposal.mdrecords why a change existsdesign.mdrecords the shape of the solutiontasks.mdcaptures the implementation trail- the spec itself turns all of that into auditable requirements
In other words, the spine is what prevents the whole setup from becoming vibes-driven architecture. If doctrine is the ethos and RFCs are the contracts, the spec layer is the point where the repo can finally say "this is what counts as correct".
The Craft and Care
Metaphorically, this represents the who of the project. Who has worked on this? What are their engineering standards, their code styles, their biases and their preferences? Are they a craftsman, are they rapidly iterating developers? The craft and care that goes into developing a project significantly influences many design choices, allowing one to tune the balance between simple, readable code and clever, intuitive magic.
This is the engineering standards layer: In the context of LLMs, this fulfills the who of the implementation. We outlay expected requirements of the individuals involved in the development process, emphasizing specializations based on roles ranging from development to reviewing to testing. craft-and-care exists to make those expectations first-class. It is where I want the repo to say, in plain language: prefer cleanup over same-repo compatibility cruft; prefer readable and explicit code over clever magic; prefer fail-fast behavior over quiet fallback unless the design really calls for graceful degradation; prefer durable fixes over expedient patches; and prefer verification depth over raw throughput. It is also where review posture lives. A project should be able to say what counts as sufficient evidence, what kinds of feedback should block a merge, and which documentation or contracts must be updated in the same change rather than deferred to "later".
In practice, I think of this pillar as the thing that keeps an AI-heavy repository from becoming operationally sloppy even when its doctrine and specs are good. Doctrine can tell an agent what kind of project this is. Legends-and-lore can tell it the intended design shape. OpenSpec can tell it what must be true. But craft-and-care is what tells it how to touch the codebase without leaving fingerprints everywhere. It is the project's answer to the question: "what does disciplined engineering look like here?"
The Lay and Land
The final pillar is topology: where everything lives, and how it all connects.
This is arguably the pillar that saves the most cognitive load day to day. A multi-tool AI setup can accumulate an irritating number of surfaces: canonical skill sources, tool-specific mirrors, checked-in defaults, ignored local runtime state, installation targets under $HOME, helper scripts, legacy agent prompts, and generated artifacts. Without a topology map, the whole thing quickly becomes the sort of system where every answer starts with "it depends what you mean by source of truth".
The lay-and-land docs are my answer to that. They map the repo as a set of layers:
- shared authoring in
skills/ - local workflow customization in
skills/personal/ - older prompt corpora in
agents/ - thin tool facades in
.claude/,.codex/,.gemini/, andopencode/ - self-knowledge in
about/ - normative requirements in
openspec/
Just as importantly, they describe the flow: author canonical assets in the repo, mirror or link them into tool-specific surfaces, then install those surfaces into the actual homes each assistant consumes. Once that is written down, it becomes much easier to resist doing silly things like editing a mirrored copy and forgetting that the real source lives elsewhere.
Aggregating these capabilities via skills
These documentation mandates are laid out in the project-shape skill. Designed in a manner encouraging progressive discovery, this allows subagents to focus on particular pillars for parallelized but focused documentation for targeted stacks within a project. The /project-shape skill also generates project-specific /heart-and-soul, /legends-and-lore, /spec-and-spine, /craft-and-care, and /lay-and-land skills which are contextualized for a given project.
This allows for several steps of progressive documentation generation:
- A project-agnostic
project-shapedefines normative standards of the shape every project should have - Generated project-specific
heart-and-soul,legends-and-lore,spec-and-spine,craft-and-care, andlay-and-landskills contextualize those pillars for a given repository
Next steps: Work planning
Now that we have defined our project shape and specifications, the next step is to decide how that gets implemented. How do we achieve the wants of our projects by translating it into code? We go through the implementation orchestration layer in LLM Project Planning and Orchestration.