Introduction
The OpenAI Car Racing gym environment is a continuous control image-based task, whereby a car is trained to navigate a randomly generated racetrack. This post describes the team's efforts in investigating differing approaches to creating an effective generalizable model, and an interactive GUI for user interpretation of model and parameter efficacy. Approaches such as Double Deep Q Learning, Policy Gradient, Advantage Actor-Critic (A2C), and Imitation Learning are taken with accompanying results analyzed, and a system built for contrasting efficacy of models allows human players to observe in real-time the impact of parameter changes or imitation-based suggested movements.
Problem Scope
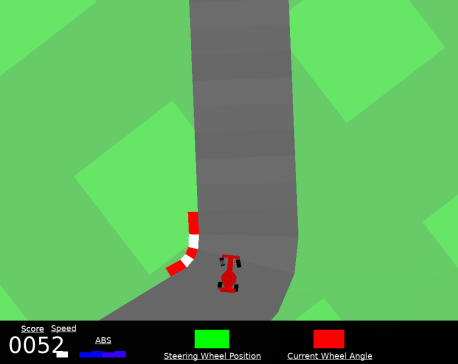
The OpenAI Car Racing Gym environment takes in continuous input, with a 96x96 pixel state and a time-to-completion based reward scheme. New racing tracks are generated every iteration - these tracks include turns of varying sharpness, and will always loop back to their starting point in a counter-clockwise manner. The environment provides a -0.1 reward per frame and +1000/N for every track tile visited, where N is the total number of tiles in the track, imposing an upper bound of 1000 for possible rewards. The controls for the car are Left, Right, Accelerate, and Brake, which are non-exclusive. Additional indicators at the bottom of the screen provided include true speed, four ABS sensors, steering wheel position, and gyroscope.
Neural Network architecture
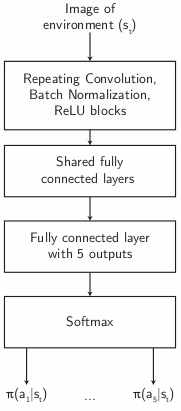
As the goal was to test our various Reinforcement learning approaches, we decided to standardize a convolutional neural network with fully connected layers with five output neurons, which are softmaxed to yield exclusive categorical values, representing the decisions (e.g. accelerate, left, right). This mimics human behaviour, with the notable exception of disallowing multiple simultaneous commands (e.g. ACCELERATE and LEFT at the same time). This is due to the nature of the gym environment designed - simultaneous pressing of keys has a very high likelihood of causing the vehicle to skid out of control.
Approaches
We implemented several Reinforcement Learning models in our initial exploration for solutions to the problem. They are described as follows:
Double Deep Q Learning
The Q learning algorithm was our first approach as an initial exploration of the feasibility of solving the racing car problem. We implemented Double Deep Q Learning, notably to avoid the problem of overestimation caused by traditional Q Learning. Double Q Learning uses two Q-value estimators, using each to update the other. These independent estimators hence each reduce overestimation, avoiding the maximization bias of using only one Q value estimator.

REINFORCE with Baseline
REINFORCE with Baseline was our second model of choice since it gives a n-step roll out estimation of V and hence, should make our training more stable as compared to Double Q Learning. Moreover, REINFORCE with Baseline tends to learn faster than REINFORCE alone.
Advantage Actor-Critic
We also chose to try out A2C as A2C tends to be more stable than Double Q Learning. On top of that, A2C updates the model more frequently than REINFORCE. A2C rolls an episode out for t max steps, updates the model, then continues again. We were hoping that by doing so, our model would be able to learn more quickly.

Imitation Learning
Taking inspiration from alternative approaches towards solving reinforcement learning problems, we decided to implement Imitation Learning as a possible way of developing an effective car racing model, as previous models yielded poor results after weeks of training. The Imitation Learning algorithm uses an underlying Double Deep Q Learning approach, but introduces an additional element via a suggested action involved. We suggest an implementation which penalizes the model reward attained if the choice taken is dissimilar to that suggested by the user. This penalty comes in the form of a modification to the reward initially yielded by the environment via direct addition or subtraction (e.g. a value of 5). This suggested implementation is as follows:

Results
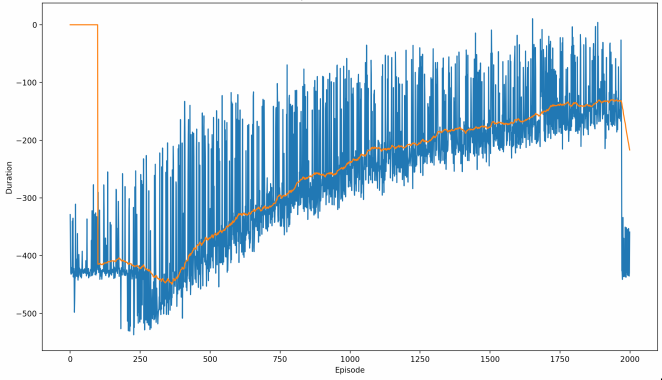
REINFORCE with Baseline: Peak mean-100 score of -200 (consistently fatal accidents)
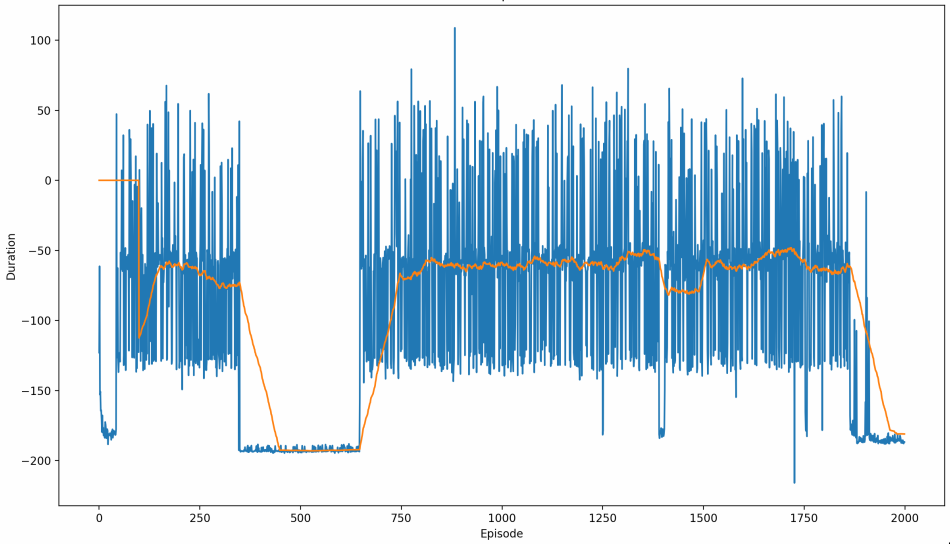
Advantage Actor-Critic: Peak mean-100 score of -50 (One successful turn, or handles long initial stretch well)
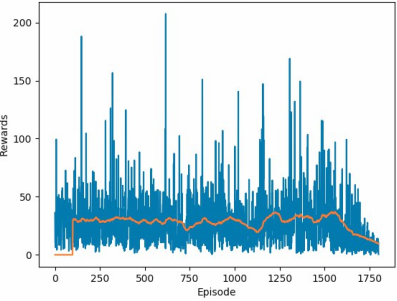
DDQN with RMSProp optimizer: Peak mean-100 score of 47.
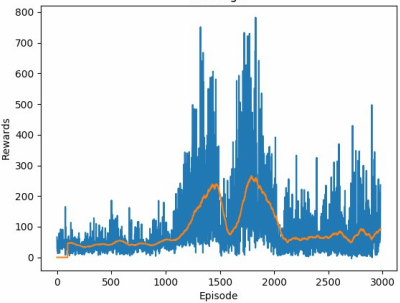
DDQN with ADAM optimizer: Peak mean-100 score of 300, with occasional successful completions of the track (generally, scores >700 are successful runs)
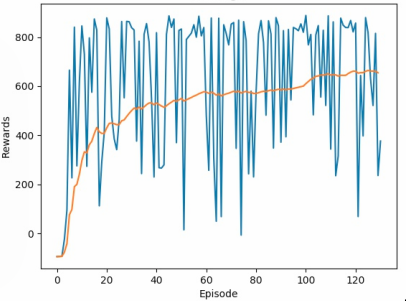
DDQN with Imitation Learning parameters: Peak mean-100 score of 620, with far more frequent completions of the track, though still not consistent. Note the vastly reduced number of training episodes needed.
Of unsupervised Reinforcement Learning algorithms, the best found was Double-Deep Q Learning with the ADAM optimizer, which managed to yield a mean-100 score of 300, among several successful completions of the track, after about 16 hours of training.
Upon subsequent exploration of feasible model generation, we found that imitation learning was an effective way of bootstrapping an initial model, achieving the same mean-100 score of 300 within thirty episodes of manual training. The use of model visualization tools such as Layer Wise Relevance Propagation also allowed us to visualize the effect of training on our models, highlighting notable landmarks on the racetrack and showing subsequent model behaviour. This, along with the developed GUI tools, will allow users to easily tweak hyperparameters and model setup to effectively tune for better generalization and results.
With our implementation of Imitation Learning, we were surprised at how quickly the model improved with the presence of human input. We hence decided to craft the user interfacing platform to show this phenomenon, allowing users to set hyperparameters before engaging in this imitation learning system. The intended user flow is for the user to input suggested actions for every frame of the episode, watching the user-guided model rapidly learn how to navigate on the racing track. Developments in the LRP can also be observed, showing the gradual appearance of notable features within the CNN over episodes. We observe that with this approach, the model is able to successfully make basic turns after only 10 episodes (about 5 minutes) of training, and able to complete the track after 20 to 25 (depending on the users). This is in strict contrast to the training time needed for other methods, such as DDQN, which required over 1400 episodes (about 12 hours) before the first successful completed run of the track.

Significant regions of the road are clearly highlighted in the LRP layer, applied to visualize the neural network's regions of significance
Conclusion
Imitation Learning proved to be the most effective approach for this environment, achieving a peak mean-100 score of 620 and reducing training time from over 12 hours (with DDQN) to roughly 5 minutes of human-guided episodes. The combination of human-suggested actions with Double Deep Q Learning allowed the model to bootstrap far more efficiently than any purely unsupervised method we tested. The accompanying GUI and LRP visualization tools make it straightforward to observe how the model develops its understanding of the track over time.